
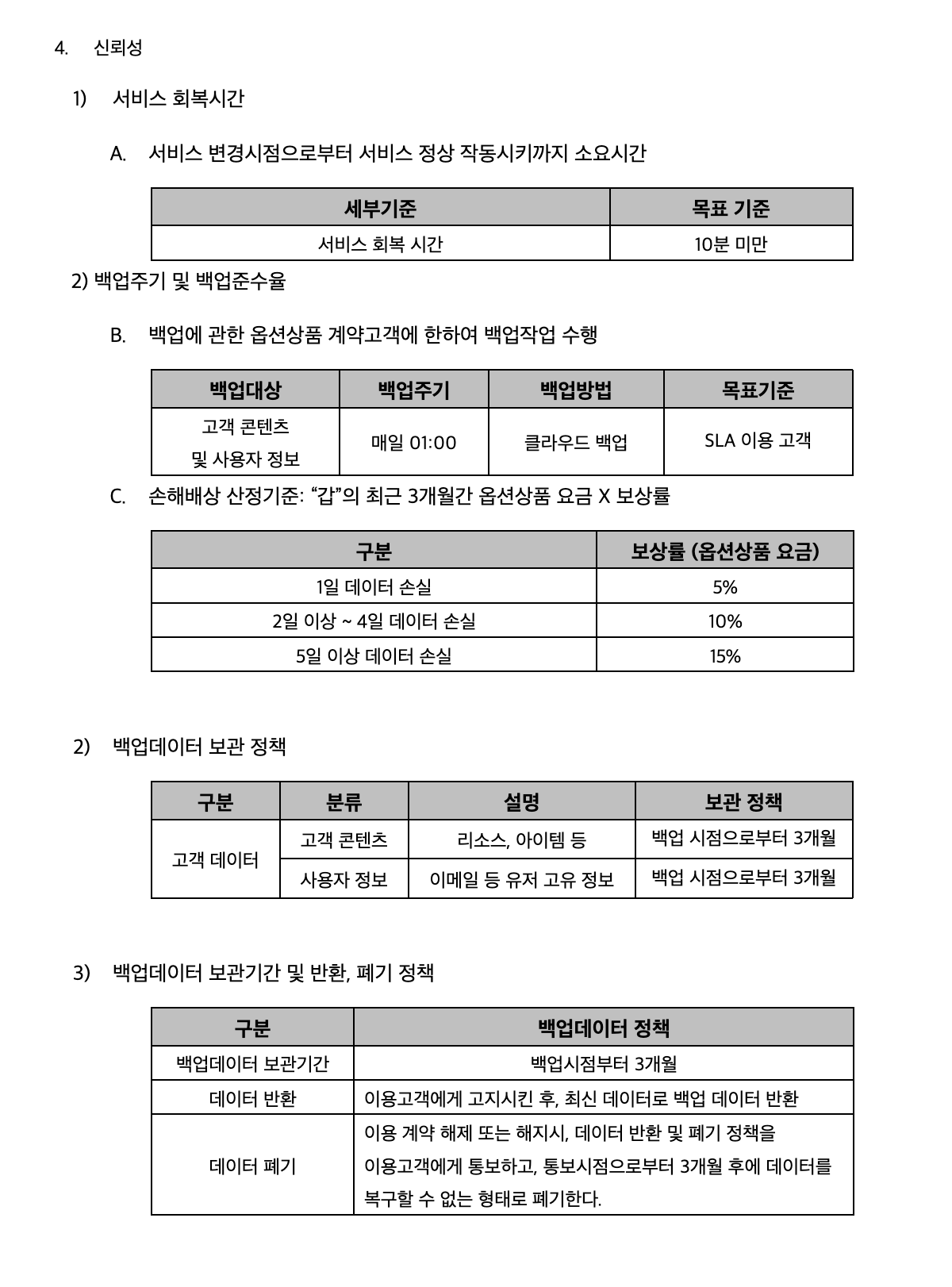
이번 글에서는 지난 번 데이터 백업에 이어 데이터 복원과 폐기는 어떻게 구현되는지에 대해 정리하려고 한다. 데이터 백업, 복원, 폐기에 대한건 사용자 측면에서 민감하게 취급되기 때문에 NIPA 인증 취득을 위해서 제출되는 여러 서류에서 세부적으로 다뤄진다. 하단에 첨부한 신뢰성 항목에 기재된 SLA(Service Level Agreement) 문서가 그 중 하나인데 데이터 보관과 폐기에 대한 정책은 3개월을 기준으로 설정했다. 서비스 회복 시간은 10분 미만으로 설정하였고, 이는 파드가 다시 Running 상태로 돌아오고 백업 압축 데이터를 복원시키는데까지 충분한 시간이다. 백업준수율은 백업되어야하는 실제 횟수와 성공한 횟수를 백분율로 계산한 수치인데 99%로 설정하였다.
별개 내용이지만 문득 '데이터 폐기와 회원탈퇴는 어떤 식으로 관리될까?' 라는 의문점이 들었다. 이게 정석이지 라는게 없다고 생각하기 때문에 작은 의견처럼 적어보자면, 회원탈퇴를 하게 되면 바로 유저를 제거하는 것이 아닌 DB 스키마에서 유저 계정이 활성화되었는지 여부를 boolean값으로 받아서 탈퇴한 사용자는 false처리를 해야하지 않나 싶다. '탈퇴된 유저의 데이터를 3개월 동안 보관하겠다'까지가 데이터 백업 안에 포함되어야할테고 3개월이 넘어간 데이터는 복원되지 않다는 것을 사용자에게 고지해준다면 이 부분에 대해서는 정책상 컴플레인도 없을 것이다.
데이터 복원
데이터를 복원하는 것이 그저 문장으로는 와닿지만 이를 어떻게 구현하는지가 고민이었다. 클라우드 스토리지에 압축된 파일들이 날짜별로 정리가 되어있고 이를 데이터베이스 파드로 가져와서 압축을 해제한 뒤에 Restore시켜야한다. 이를 구현하기 위해서 '어느 시점'에 복원을 시켜줄지를 먼저 생각하게 되었는데 이는 자연스럽게 배포된 StatefulSet 리소스의 생애주기를 관리하는 속성값이 yaml에 있는지를 찾아보게 되었다.
보란듯이 공식 문서에 친절히 작성되어있다. 파드 및 컨테이너의 생애주기를 제어하기 위하여 lifecycle이라는 속성값을 가져와서 재시작될 때마다 특정 동작을 가능케해주는 postStart를 사용할 수 있다.

신나는 마음으로 바로 테스트 진행해보기..! 처음에는 핑을 찍는 것으로 테스트를 해보았고 결과적으로는 마운트된 볼륨의 지정된 경로를 찾아가서 오늘 날짜를 기준으로 가장 가까운 날짜의 압축 폴더를 먼저 찾는다. mongoDB를 쓰고 있기 때문에 mongorestore 커맨드를 통해 복원시켜준다! 그 후, 압축 해제한 파일은 제거해준다.
spec:
restartPolicy: Always
containers:
- name: sample
image: mongo:4.2
ports:
- containerPort: 27017
lifecycle:
postStart:
exec:
command:
- "/bin/sh"
- "-c"
- |
LATEST_BACKUP=$(find /data/sample -type f -name '*.tar.gz' | sort -r | head -n 1)
BACKUP_DATE=$(basename "$LATEST_BACKUP" .tar.gz)
tar -xzvf "$LATEST_BACKUP" -C /data/sample
mongorestore --uri=mongodb://sample-0.sample-svc.default.svc.cluster.local:27017 --db=sample /data/sample/$BACKUP_DATE/sample
rm -rf /data/sample/$BACKUP_DATE
volumeMounts:
- name: sample-volume
mountPath: /data/sample
volumes:
- name: sample-volume
persistentVolumeClaim:
claimName: sample-pvc생각보다 깔끔하지 않나? 재시작되는 시점마다 복원을 시켜주면 된다. 그치만 한계점으로는 매일 00시 기준으로 백업을 해준다면, 복원되는 시간 사이에 발생된 변경사항은 사용자에게 제공될 수 없다는 점이다. 이를 위해서 대기업에서는 더욱 세분화된 백업 기법을 활용하는데 꽤나 흥미롭다. 이 부분은 추후에 더 정리하여 새 게시글로 작성하고 싶다.
데이터 폐기
이제 폐기만 구현하면 데이터 백업 관리에 대한 모든 프로세스가 마치게 된다. 폐기는 어느 시점에 해주면 좋을까? 최대한 프로세스는 적은 시점으로 통일되면 좋다. 데이터 백업되는 시점에 매일 한 번씩 주기적으로 업데이트되기 때문에 이 시점에 전체 폴더를 필터링해서 기한을 넘은 파일은 제거해주면 된다. 즉, 폐기 프로세스는 Cronjob에 들어가면 된다.
spec:
backoffLimit: 1
template:
spec:
containers:
- name: sample
image: mongo:4.2
args:
- /bin/sh
- -c
- |
#!/bin/sh
# 데이터 백업 로직
TIMESTAMP=$(date +%Y%m%d)
BACKUP_DIR="/backup/$TIMESTAMP"
mongodump --host sample-0.sample-svc.default.svc.cluster.local:27017 --db sample --out $BACKUP_DIR
tar -zcvf "/backup/${TIMESTAMP}.tar.gz" -C "/backup" "$TIMESTAMP"
rm -rf "$BACKUP_DIR"
# 데이터 폐기 로직
DELETE_DATE=$(date -d "90 days ago" +%Y%m%d)
find /backup -type f -name "*.tar.gz" | while read FILE; do
FILE_DATE=$(basename "$FILE" .tar.gz)
if [ "$FILE_DATE" -lt "$DELETE_DATE" ]; then
rm -f "$FILE"
fi
done
volumeMounts:
- name: sample-volume
mountPath: /sample
volumes:
- name: sample-volume
persistentVolumeClaim:
claimName: sample-pvc
restartPolicy: OnFailure테스트까지 완료. 그리고 실제 클러스터에 반영! 데이터 백업, 복원, 폐기에 대한 구현을 완료되었고 실제 테스트를 진행하면서 백업준수율과 파드가 재시작되어 유저가 로그인 성공하는 시점까지 10분 이내인지까지 모두 성공적으로 마쳤다. '신뢰성'에 대한 항목이 필자는 SaaS 요건 중에 가장 까다로웠는데 완료되기까지 기한은 조금 걸렸어도 즐겁고 보람찬 경험이었다. 다음은 확장성을 다뤄볼까 한다!
마치며
프론트엔드 개발자가 데이터 백업 프로세스를 구현하는게 어떤 도움이 될지 고민을 하면서 NIPA 인증 취득하는 3개월을 보냈다. 일차원적으로는 즐겁다. 아직도 개발은 재밌고 모르는 것을 해내고 테스트까지 하면서 꼼꼼하게 살펴볼 때 즐겁다는 생각을 한다. 면접에서 React 프레임워크에 대한 질문을 못하는데 데이터 백업 구현에 대해 한 경험이 그 어떤 회사 면접관에게 어필이 될까? 그런 사람이 되는 것을 경계하고 프론트 공부를 더 다져야겠다는 생각을 했다. 인프라 업무 담당에 대해서는 현재 회사 내 나의 포지션에 대한 것들을 꼼꼼하게 채우되 더 넓은 시야를 경험했다는 것만을 가져가도 충분하겠다 싶다.